
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- mysql
- 안드로이드
- 인공지능
- 블로그
- 데이터베이스
- ubuntu 12.04
- 우분투
- 단통법
- 해외직구
- 손민한
- 프로야구
- Git
- 문파문파
- 애플
- NC다이노스
- 조세피난처
- 리뷰
- 야구
- python
- 타이젠
- 문파문파 공략
- 태그를 입력해 주세요.
- NC 다이노스
- Tizen
- 국정원
- arm
- ubuntu
- Linux
- 김경문
- 뉴스타파
- Today
- Total
꿈꾸는 사람.
'NFL Big Data Bowl 2024' 캐글 경진대회 참여하기 (1) 본문
캐글 경진대회 참여기: 프로그래머에서 데이터 분석가로의 여정
오늘은 데이터 분석가를 준비하는 프로그래머로써 'NFL Big Data Bowl 2024' 대회에 참여하기로 결정한 흥미진진한 이야기를 여러분과 공유하려 합니다.
1. 캐글과의 첫 만남
데이터 분석에 필요한 데이터셋을 찾던 중 캐글을 알게되어 가입하여 데이터 분석의 세계에 첫발을 디뎠습니다.
캐글은 데이터 과학자와 머신 러닝 엔지니어를 위한 훌륭한 플랫폼으로, 전 세계의 다양한 데이터와 문제를 해결할 기회를 제공합니다.
2. NFL Big Data Bowl 2024
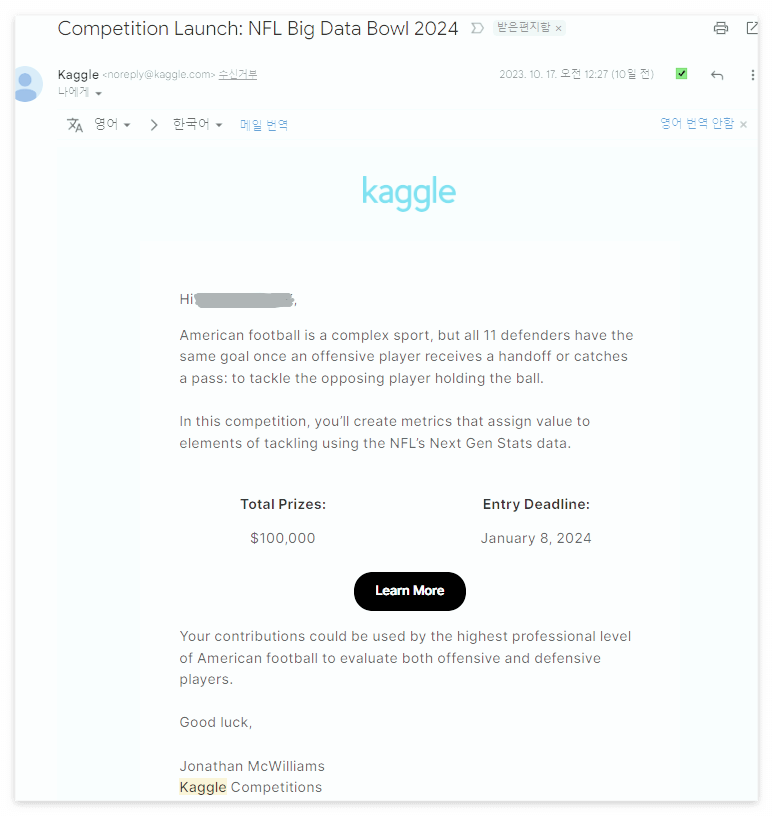
가입 후 얼마 지나지 않아 'NFL Big Data Bowl 2024' 대회 참여 초대 메일을 받았습니다.
이 대회는 NFL 데이터를 사용하여 미식축구 선수들의 경기력을 분석하고 예측하는 것이 주된 목표이며 상금도 십만 달러입니다. 이 대회는 많은 데이터 분석가와 프로그래머들에게 흥미로운 도전이 될 것입니다.
3. 준비 과정
대회에 참여하기 위해서는 몇 가지 준비 과정을 거쳐야 합니다.
데이터 이해
우선 제공된 데이터를 철저히 이해하는 것이 중요합니다. 이전 대회에서는 러닝백, 디펜시브백, 스페셜 팀, 패스 러시 플레이 등을 분석했으나 Next Gen Stats 선수 추적 데이터를 사용하여 실용적이고 창의적이며 새로운 통계를 생성했습니다.
NFL 데이터는 선수들의 위치, 움직임, 경기 상황 등 다양한 정보를 포함하고 있습니다. 이 데이터를 잘 이해하고 분석하는 것이 좋은 결과를 얻기 위한 첫걸음입니다.
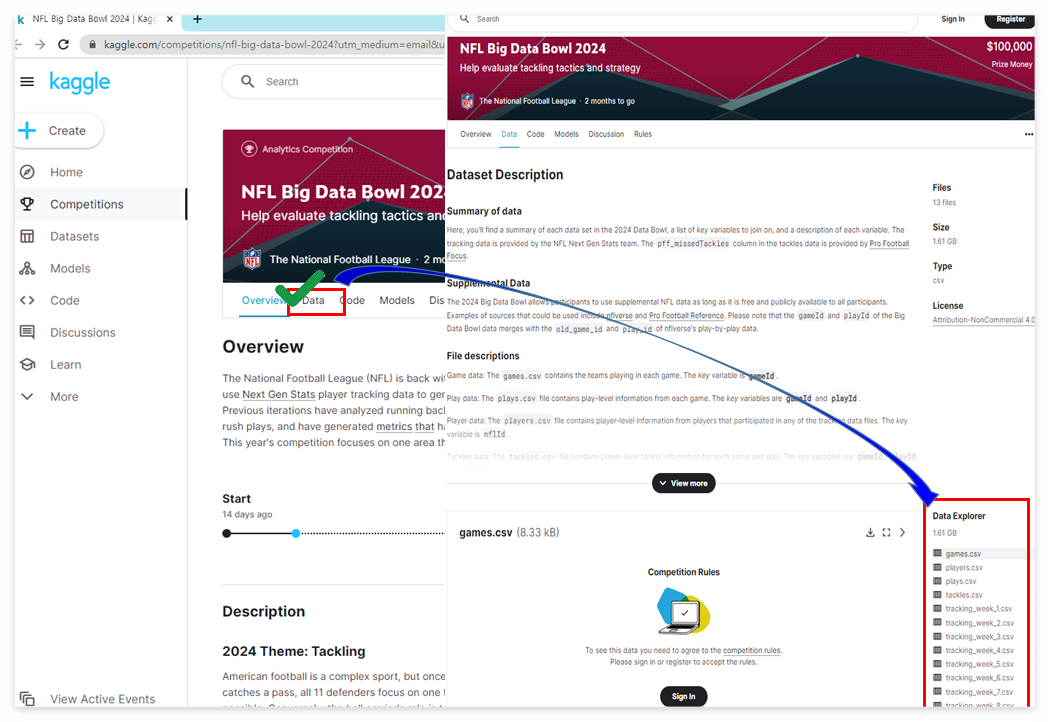
경진대회 규칙을 준수하는 내용에 동의 후 아래와 같이 데이터를 받아서 분석을 시작합니다.
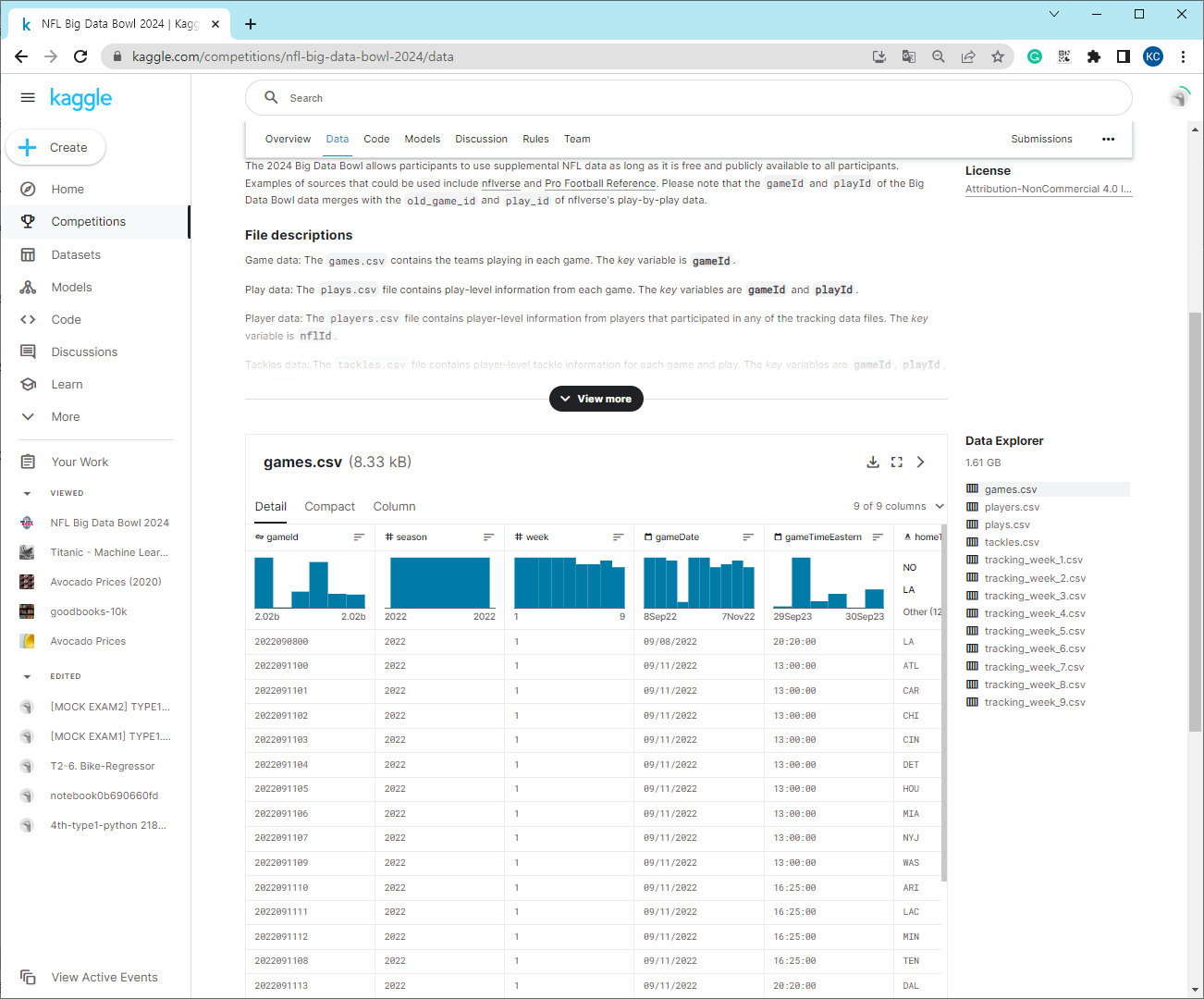
데이터셋을 읽고 다음과 같은 내용을 파악해본다.
- 데이터의 처음 몇 행을 확인하여 구조를 이해합니다.
- 데이터의 기술 통계를 확인하여 각 특성의 분포를 파악합니다.
- 결측치의 존재 여부를 확인합니다.
- 각 특성의 고유한 값과 그 분포를 확인합니다.
- 데이터 간의 관계를 파악하기 위해 적절한 시각화를 수행합니다.
데이터 전처리
데이터를 분석하기 전에는 데이터 전처리 과정을 거쳐야 합니다. 이 과정에는 누락된 값 처리, 이상치 제거, 데이터 정규화 등이 포함됩니다.
데이터 전처리는 결측값, 이상값을 처리하는 데이터 정제와 데이터 유형을 변환하거나 범위를 표준화 또는 정규화하는 등의 데이터 변환으로 이루어집니다.
모델 선택 및 학습
전처리된 데이터를 바탕으로 적절한 머신 러닝 모델을 선택하고 학습합니다. 여러 가지 모델을 실험해 보고, 교차 검증을 통해 모델의 성능을 평가합니다.
경진대회에 1위를 차지한 솔루션들은 Ensemble 모델, 딥러닝 모델 등의 분석모형을 사용하여 다양한 하이퍼 파라미터를 조정한 결과를 얻습니다.
각 대회의 1등 솔루션은 보통 대회 종료 후 공유되며, 다른 참가자들과 지식을 공유하는 목적으로 사용됩니다.
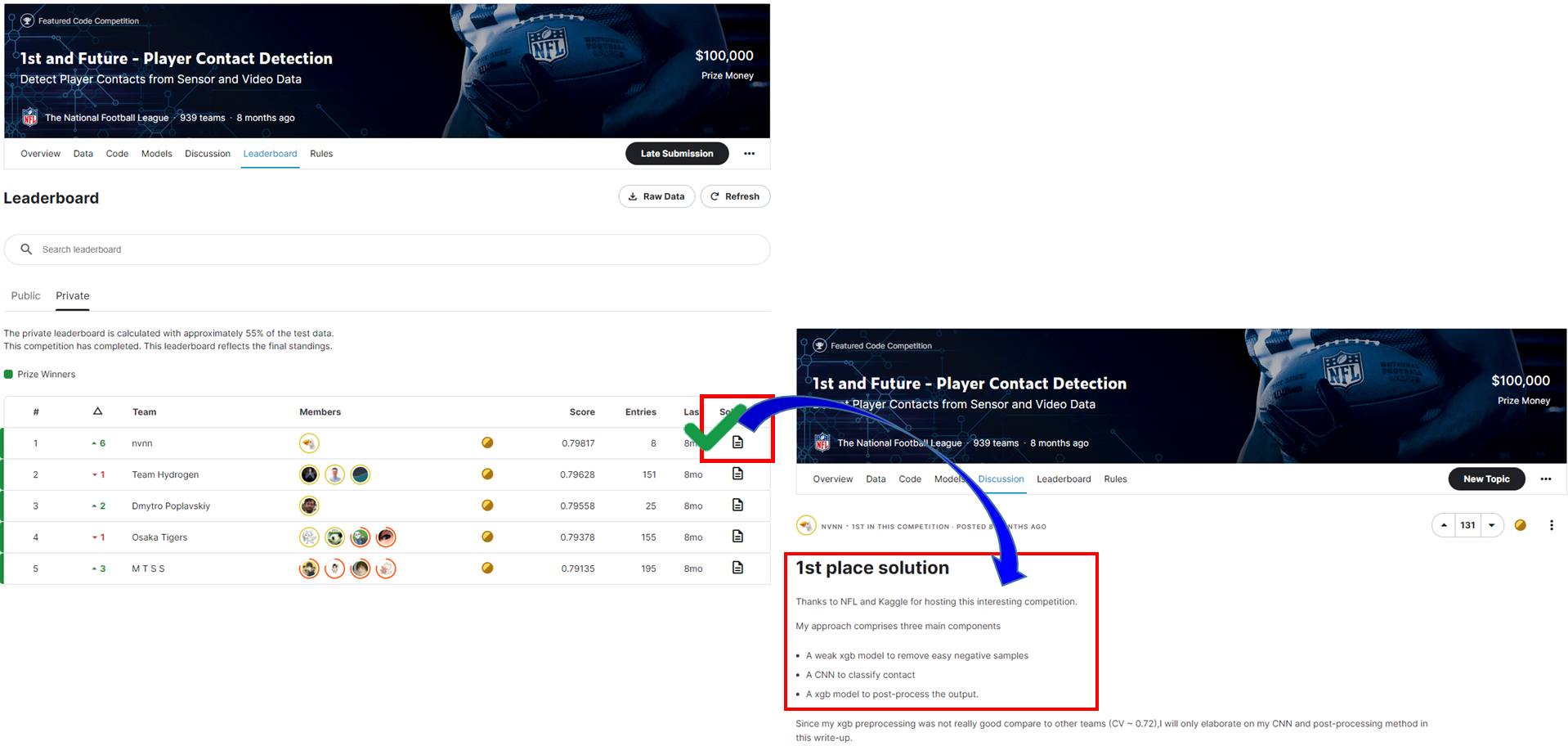
"1st and Future - Player Contact Detection"의 대회에서 1위인 솔루션은 아래 3개의 모델을 사용합니다.
- 쉬운 네거티브 샘플을 제거하기 위한 약한 xgb 모델
- 접촉을 분류하는 CNN
- 출력을 사후 처리하는 xgb 모델
결과 제출 및 평가
학습된 모델을 사용하여 결과를 예측하고, 이를 캐글에 제출합니다. 제출된 결과는 리더보드에서 확인할 수 있으며, 다른 참가자들과의 성능을 비교할 수 있습니다.
피드백 및 반복
제출한 결과에 대한 피드백을 받고, 필요한 경우 모델을 수정하거나 개선하여 다시 제출합니다.
대회가 종료될 때까지 이 과정을 반복합니다.
대회 종료 및 결과 확인
대회가 종료되면 최종 순위와 결과를 확인합니다.
경험 공유
참여한 대회에서 얻은 경험과 지식을 Kaggle의 Discussion 탭이나 개인 블로그 등에 공유할 수 있습니다.
4. 끝없는 도전
'NFL Big Data Bowl 2024' 경진대회의 참가를 단순히 경쟁을 넘어서 학습과 성장의 기회로 생각합니다.
다른 참가자들의 솔루션을 분석하고, 커뮤니티와 지식을 공유하며, 데이터 분석가로서의 역량을 키울 수 있는 좋은 기회가 될 것입니다.
마무리
이제 캐글 경진대회의 세계에 한 발짝 다가섰습니다. 캐글 경진대회 참여가 데이터 분석에 흥미와 동기를 부여할 것입니다.
데이터의 세계는 끝없이 넓고, 우리가 배울 것은 무궁무진합니다.
다음 포스팅을 통해 데이터 분석을 준비하는 상세한 과정을 통해 계속해서 도전하고, 배우고, 성장해 나가는 모습을 보이고자 합니다.
'Data Science' 카테고리의 다른 글
| 통계학에서 기술 통계학 (0) | 2021.07.21 |
|---|---|
| 확률과 베이지안 확률 (0) | 2021.04.30 |

