
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- Linux
- NC다이노스
- 리뷰
- Git
- ubuntu 12.04
- 안드로이드
- 타이젠
- 해외직구
- 단통법
- Tizen
- mysql
- 데이터베이스
- 야구
- 국정원
- 손민한
- arm
- 문파문파
- 애플
- 블로그
- 문파문파 공략
- ubuntu
- 조세피난처
- 김경문
- 뉴스타파
- 태그를 입력해 주세요.
- python
- NC 다이노스
- 프로야구
- 인공지능
- 우분투
Archives
- Today
- Total
꿈꾸는 사람.
pandas의 Groupby() 알아보기 본문
반응형
1. groupby 정의와 개요
pandas.DataFrame.groupby() (또는 Series.groupby())는 Split‑Apply‑Combine 패턴을 구현한 핵심 메서드이다.
- Split : 하나 이상의 “키”(열 값, 인덱스 레벨, 범위, 함수 등)에 따라 데이터를 논리적으로 그룹으로 나눈다.
- Apply : 각 그룹에 대해 집계(aggregation), 변환(transformation), 필터링(filtering) 같은 연산을 독립적으로 수행한다.
- Combine : 처리를 마친 결과를 단일 Series 또는 DataFrame으로 재구성(combine)하여 반환한다.
이 과정 덕분에 반복문을 작성하지 않고도 대량 데이터에 대한 조건별 연산을 간결·고속으로 수행할 수 있다.
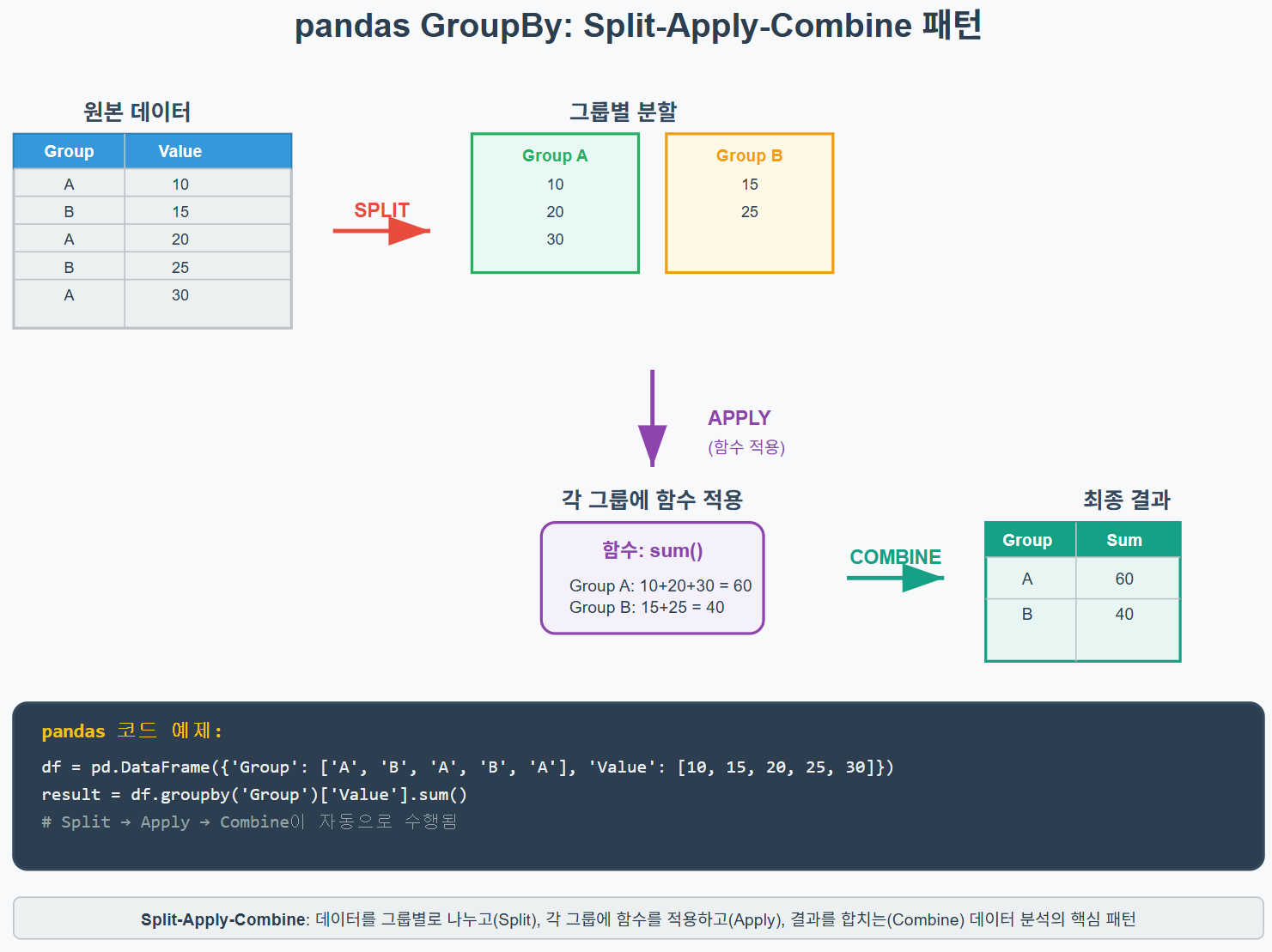
2. 주요 기능 3가지와 코드 예시
아래 예시는 공통적으로 다음 샘플 데이터를 사용한다.
import pandas as pd
df = pd.DataFrame({
'dept': ['A', 'A', 'B', 'B', 'C', 'C'],
'employee': ['Kim', 'Lee', 'Park', 'Choi', 'Jung', 'Han'],
'salary': [5100, 6200, 4500, 5200, 6100, 5800],
'years': [3, 5, 2, 4, 6, 5]
})
| dept | employee | salary | years |
| A | Kim | 5100 | 3 |
| A | Lee | 6200 | 5 |
| B | Park | 4500 | 2 |
| B | Choi | 5200 | 4 |
| C | Jung | 6100 | 6 |
| C | Han | 5800 | 5 |
2‑1 Aggregation (집계)
목적 : 그룹별로 하나의 스칼라 값을 산출해 데이터 크기를 줄임.
# 부서별 평균 급여와 최대 경력년수 한 번에 집계
agg_df = (
df.groupby('dept')
.agg(avg_salary=('salary', 'mean'),
max_years=('years', 'max'))
)
print(agg_df)| dept | avg_salary | max_yeares |
| A | 5650.0 | 5 |
| B | 4850.0 | 4 |
| C | 5950.0 | 6 |
2‑2 Transformation (변환)
목적 : 각 그룹을 가공하되 원본과 동일한 행 수를 유지해 그룹별 정규화·파생 변수 생성에 활용.
# 부서별 급여 평균을 뺀 편차(중심화) 파생 변수 추가
df['salary_dev'] = (
df.groupby('dept')['salary']
.transform(lambda s: s - s.mean())
)
print(df[['dept', 'employee', 'salary', 'salary_dev']])| dept | employee | salary | salary_dev |
| A | Kim | 5100 | -550.0 |
| A | Lee | 6200 | +550.0 |
| B | Park | 4500 | -350.0 |
| B | Choi | 5200 | +350.0 |
| C | Jung | 6100 | +150.0 |
| C | Han | 5800 | -150.0 |
transform 은 벡터를 반환하므로 결과가 원본 행과 1 : 1 대응한다.
이를 통해 모델 입력용 표준화, 랭킹, 누적합(rolling) 등을 간단히 구현한다.
2‑3 Filtering (필터링)
목적 : 그룹별 조건식을 평가해 조건을 만족한 그룹만 보존하여 원본과 동일한 스키마의 DataFrame을 반환
# 평균 급여가 5,500 이상인 부서만 유지
high_pay = (
df.groupby('dept')
.filter(lambda g: g['salary'].mean() >= 5500)
)
print(high_pay[['dept', 'employee', 'salary']])| dept | employee | salary |
| A | Kim | 5100 |
| A | Lee | 6200 |
| C | Jung | 6100 |
| C | Han | 5800 |
참고로 high_pay 전체의 내용은 아래와 같다.

filter는 그룹 단위로 불리언 조건을 평가한 뒤, 조건이 True인 그룹만 병합한다.
(filter는 “그룹을 선택 또는 제외”하기 위한 도구)
시계열 이상치 제거, 최소 표본 수 확보 등에서 유용하다.
3. 핵심 포인트 요약
| 기능 | 평가단위 | 반환 크기 | 대표 함수 | 활용 시나리오 |
| Aggregation | 그룹 | 그룹 수 × 열 수 | sum, mean, agg | KPI 산출, 리포팅 |
| Transformation | 행 | 원본과 동일 | transform, rank, rolling | 그룹별 정규화, 파생 변수 |
| Filtering | 그룹 | 가변 (0 ~ 원본) | filter | 그룹 품질 관리, 이상치·노이즈 제거 |
groupby를 집계·변환·필터 3축으로 체계화해 두면, 실무·시험 모두에서 빠르고 우아한 솔루션을 설계할 수 있다.
반응형
'Python' 카테고리의 다른 글
| [Pandas Groupby] 타이타닉 생존율 분석 (그룹별 상위 N개 추출 패턴) (0) | 2026.01.07 |
|---|---|
| Python으로 테이블의 열을 가져오기 (2) | 2025.07.05 |
| python 패키지 - pandas 개요 (0) | 2024.11.23 |
| 데이터 전처리에 최빈값 (mode) 적용하기 (0) | 2022.11.21 |
| Python::프로야구 팀순위 분석 (2) | 2022.07.19 |
'Python' Related Articles
more



Comments