
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- arm
- python
- 김경문
- 손민한
- 프로야구
- NC다이노스
- mysql
- 애플
- 해외직구
- Linux
- 데이터베이스
- NC 다이노스
- 야구
- 타이젠
- 리뷰
- 조세피난처
- 블로그
- 국정원
- 뉴스타파
- ubuntu
- ubuntu 12.04
- 문파문파 공략
- 문파문파
- Tizen
- 태그를 입력해 주세요.
- 단통법
- Git
- 우분투
- 인공지능
- 안드로이드
- Today
- Total
꿈꾸는 사람.
시계열 예측(Time Series Forecasting) 개요 본문
시계열 정의
시계열(time series)은 시간에 따라 순차적으로 수행되는 일련의 관찰이다.
시계열 데이터는 시간의 흐름에 따라 관측된 데이터이다.
시계열 분석(Time Series Analysis)은 시계열 데이터를 분석하는 것이고,
시계열 예측(Time Series Forecasting)은 시계열의 정보를 사용하여 해당 시리즈의 미래 값을 예측한다.
시계열 데이터 표시
시계열에서 지연 시간 또는 지연이라고 하는 과거의 시간은 현재 시간에 비해 음수이고,
미래의 시간은 예측하는 데 관심이 있고 현재 시간에 비해 양수이다.
과거와 미래의 시간의 표현은 다음과 같다.
- t-n : 이전 또는 지연 시간 (예 : 이전 시간에 대한 t-1).
- t : 현재 시간 및 참조 지점.
- t + n : 미래 또는 예측 시간 (예 : 다음 시간의 경우 t + 1).
예를 들어 이전 시간은 t-1이고 그 이전 시간은 t-2이다.
예를 들어 다음 시간은 t + 1이고 그 이후 시간은 t + 2이다.
시계열 분석(Time Series Analysis)
데이터 세트를 이해하는 것이 시계열 분석이다.
예측을 하는 데 도움이 될 수 있지만 필수 사항은 아니다.
설명적 모델링 또는 시계열 분석에서 시계열은 계절적 패턴, 추세, 외부 요인과의 관계 등의 측면에서 구성 요소를 결정하기 위해 모델링 된다.
시계열 분석의 주요 목표는 표본 데이터에서 적절한 설명을 제공하는 수학적 모델을 개발하는 것이다.
시계열 예측(Time Series Forecasting)
시계열 예측은 시계열의 정보를 사용하여 해당 시리즈의 미래 값을 예측한다.
예측에는 과거 데이터에 대한 모델을 구하고 이를 사용하여 미래 관찰을 예측하는 것을 포함한다.
시계열 예측 모델의 기능은 미래 예측 성능에 의해 결정된다.
시계열의 구성 요소(Components of Time Series)
- 레벨(Level) 직선인 경우 시리즈의 기준 값
- 추세(Trend) 시간에 따른 계열의 선택적이고 종종 선형 증가 또는 감소 동작
- 계절성(Seasonality) 선택적 반복 패턴 또는 시간 경과에 따른 행동 주기
- 소음(Noise) 모델로 설명할 수 없는 관측치의 선택적 변동성
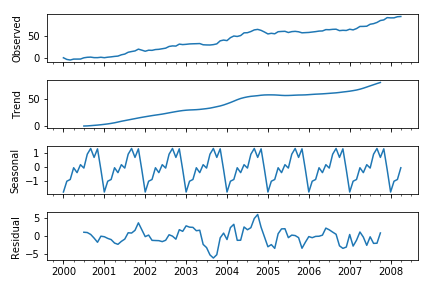
관측된 데이터에서 추세와 계절성을 제거하고 남은 잔차로 시계열 자료의 특성을 이해하고 예측에 활용한다.
이렇게 시계열 분해(time series decomposition)하는 이유는 다음 글에서 정상성(stationarity)을 통해 설명한다.
'AI > Machine Learning' 카테고리의 다른 글
| 인공지능에서의 멀티모달(Multimodal) (0) | 2023.09.14 |
|---|